IF YOU WOULD LIKE TO GET AN ACCOUNT, please write an
email to Administrator. User accounts are meant only to access repo
and report issues and/or generate pull requests.
This is a purpose-specific Git hosting for
BaseALT
projects. Thank you for your understanding!
Только зарегистрированные пользователи имеют доступ к сервису!
Для получения аккаунта, обратитесь к администратору.
Macro fusion merges two instructions to a single micro-op. Intel core
platform performs this hardware optimization under limited
circumstances.
For example, CMP + JCC can be "fused" and executed /retired together.
While with sampling this can result in the sample sometimes being on the
JCC and sometimes on the CMP. So for the fused instruction pair, they
could be considered together.
On Nehalem, fused instruction pairs:
cmp/test + jcc.
On other new CPU:
cmp/test/add/sub/and/inc/dec + jcc.
This patch adds an x86-specific function which checks if 2 instructions
are in a "fused" pair. For non-x86 arch, the function is just NULL.
Changelog:
v4: Move the CPU model checking to symbol__disassemble and save the CPU
family/model in arch structure.
It avoids checking every time when jump arrow printed.
v3: Add checking for Nehalem (CMP, TEST). For other newer Intel CPUs
just check it by default (CMP, TEST, ADD, SUB, AND, INC, DEC).
v2: Remove the original weak function. Arnaldo points out that doing it
as a weak function that will be overridden by the host arch doesn't
work. So now it's implemented as an arch-specific function.
Committer fix:
Do not access evsel->evlist->env->cpuid, ->env can be null, introduce
perf_evsel__env_cpuid(), just like perf_evsel__env_arch(), also used in
this function call.
The original patch was segfaulting 'perf top' + annotation.
But this essentially disables this fused instructions augmentation in
'perf top', the right thing is to get the cpuid from the running kernel,
left for a later patch tho.
Signed-off-by: Yao Jin <yao.jin@linux.intel.com>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1499403995-19857-2-git-send-email-yao.jin@linux.intel.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The option 'show-total-period' works fine without a option '-l'. But if
running 'perf annotate --stdio -l --show-total-period', you can see a
problem showing only zero '0' for number of samples.
Before:
$ perf annotate --stdio -l --show-total-period
...
0 : 400816: push %rbp
0 : 400817: mov %rsp,%rbp
0 : 40081a: mov %edi,-0x24(%rbp)
0 : 40081d: mov %rsi,-0x30(%rbp)
0 : 400821: mov -0x24(%rbp),%eax
0 : 400824: mov -0x30(%rbp),%rdx
0 : 400828: mov (%rdx),%esi
0 : 40082a: mov $0x0,%edx
...
The reason is it was missed to set number of samples of
source_line_samples, so set it ordinarily.
After:
$ perf annotate --stdio -l --show-total-period
...
3 : 400816: push %rbp
4 : 400817: mov %rsp,%rbp
0 : 40081a: mov %edi,-0x24(%rbp)
0 : 40081d: mov %rsi,-0x30(%rbp)
1 : 400821: mov -0x24(%rbp),%eax
2 : 400824: mov -0x30(%rbp),%rdx
0 : 400828: mov (%rdx),%esi
1 : 40082a: mov $0x0,%edx
...
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Martin Liska <mliska@suse.cz>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Wang Nan <wangnan0@huawei.com>
Fixes: 0c4a5bcea4 ("perf annotate: Display total number of samples with --show-total-period")
Link: http://lkml.kernel.org/r/1490703125-13643-1-git-send-email-treeze.taeung@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
If jump target is outside of function range, perf is not handling it
correctly. Especially when target address is lesser than function start
address, target offset will be negative. But, target address declared to
be unsigned, converts negative number into 2's complement. See below
example. Here target of 'jumpq' instruction at 34cf8 is 34ac0 which is
lesser than function start address(34cf0).
34ac0 - 34cf0 = -0x230 = 0xfffffffffffffdd0
Objdump output:
0000000000034cf0 <__sigaction>:
__GI___sigaction():
34cf0: lea -0x20(%rdi),%eax
34cf3: cmp -bashx1,%eax
34cf6: jbe 34d00 <__sigaction+0x10>
34cf8: jmpq 34ac0 <__GI___libc_sigaction>
34cfd: nopl (%rax)
34d00: mov 0x386161(%rip),%rax # 3bae68 <_DYNAMIC+0x2e8>
34d07: movl -bashx16,%fs:(%rax)
34d0e: mov -bashxffffffff,%eax
34d13: retq
perf annotate before applying patch:
__GI___sigaction /usr/lib64/libc-2.22.so
lea -0x20(%rdi),%eax
cmp -bashx1,%eax
v jbe 10
v jmpq fffffffffffffdd0
nop
10: mov _DYNAMIC+0x2e8,%rax
movl -bashx16,%fs:(%rax)
mov -bashxffffffff,%eax
retq
perf annotate after applying patch:
__GI___sigaction /usr/lib64/libc-2.22.so
lea -0x20(%rdi),%eax
cmp -bashx1,%eax
v jbe 10
^ jmpq 34ac0 <__GI___libc_sigaction>
nop
10: mov _DYNAMIC+0x2e8,%rax
movl -bashx16,%fs:(%rax)
mov -bashxffffffff,%eax
retq
Signed-off-by: Ravi Bangoria <ravi.bangoria@linux.vnet.ibm.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Chris Riyder <chris.ryder@arm.com>
Cc: Kim Phillips <kim.phillips@arm.com>
Cc: Markus Trippelsdorf <markus@trippelsdorf.de>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Naveen N. Rao <naveen.n.rao@linux.vnet.ibm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Taeung Song <treeze.taeung@gmail.com>
Cc: linuxppc-dev@lists.ozlabs.org
Link: http://lkml.kernel.org/r/1480953407-7605-3-git-send-email-ravi.bangoria@linux.vnet.ibm.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
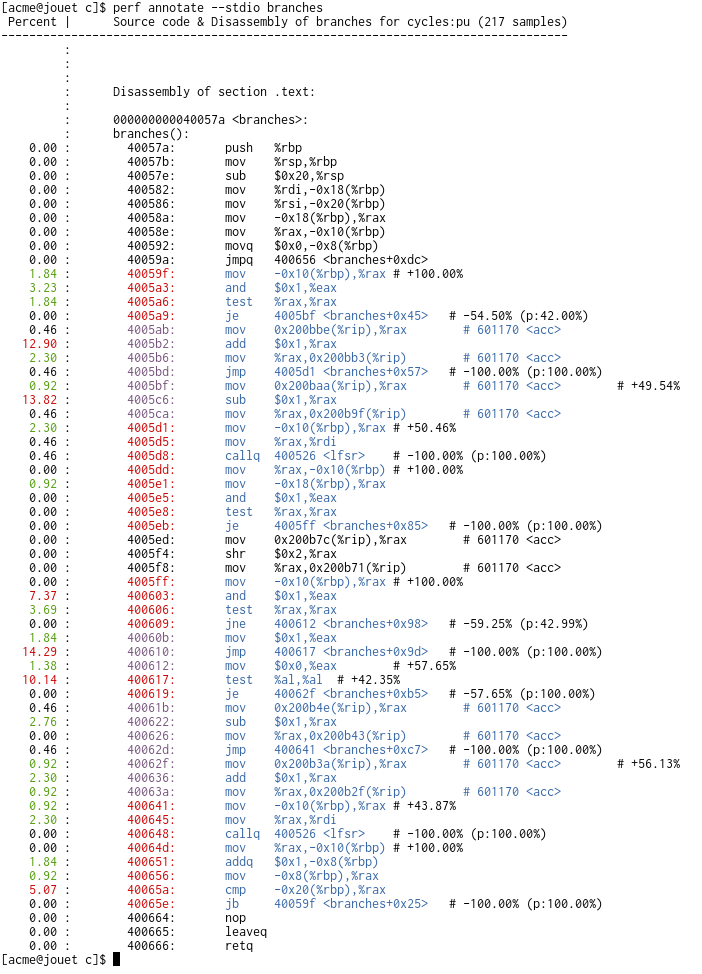
I wanted to know the hottest path through a function and figured the
branch-stack (LBR) information should be able to help out with that.
The below uses the branch-stack to create basic blocks and generate
statistics from them.
from to branch_i
* ----> *
|
| block
v
* ----> *
from to branch_i+1
The blocks are broken down into non-overlapping ranges, while tracking
if the start of each range is an entry point and/or the end of a range
is a branch.
Each block iterates all ranges it covers (while splitting where required
to exactly match the block) and increments the 'coverage' count.
For the range including the branch we increment the taken counter, as
well as the pred counter if flags.predicted.
Using these number we can find if an instruction:
- had coverage; given by:
br->coverage / br->sym->max_coverage
This metric ensures each symbol has a 100% spot, which reflects the
observation that each symbol must have a most covered/hottest
block.
- is a branch target: br->is_target && br->start == add
- for targets, how much of a branch's coverages comes from it:
target->entry / branch->coverage
- is a branch: br->is_branch && br->end == addr
- for branches, how often it was taken:
br->taken / br->coverage
after all, all execution that didn't take the branch would have
incremented the coverage and continued onward to a later branch.
- for branches, how often it was predicted:
br->pred / br->taken
The coverage percentage is used to color the address and asm sections;
for low (<1%) coverage we use NORMAL (uncolored), indicating that these
instructions are not 'important'. For high coverage (>75%) we color the
address RED.
For each branch, we add an asm comment after the instruction with
information on how often it was taken and predicted.
Output looks like (sans color, which does loose a lot of the
information :/)
$ perf record --branch-filter u,any -e cycles:p ./branches 27
$ perf annotate branches
Percent | Source code & Disassembly of branches for cycles:pu (217 samples)
---------------------------------------------------------------------------------
: branches():
0.00 : 40057a: push %rbp
0.00 : 40057b: mov %rsp,%rbp
0.00 : 40057e: sub $0x20,%rsp
0.00 : 400582: mov %rdi,-0x18(%rbp)
0.00 : 400586: mov %rsi,-0x20(%rbp)
0.00 : 40058a: mov -0x18(%rbp),%rax
0.00 : 40058e: mov %rax,-0x10(%rbp)
0.00 : 400592: movq $0x0,-0x8(%rbp)
0.00 : 40059a: jmpq 400656 <branches+0xdc>
1.84 : 40059f: mov -0x10(%rbp),%rax # +100.00%
3.23 : 4005a3: and $0x1,%eax
1.84 : 4005a6: test %rax,%rax
0.00 : 4005a9: je 4005bf <branches+0x45> # -54.50% (p:42.00%)
0.46 : 4005ab: mov 0x200bbe(%rip),%rax # 601170 <acc>
12.90 : 4005b2: add $0x1,%rax
2.30 : 4005b6: mov %rax,0x200bb3(%rip) # 601170 <acc>
0.46 : 4005bd: jmp 4005d1 <branches+0x57> # -100.00% (p:100.00%)
0.92 : 4005bf: mov 0x200baa(%rip),%rax # 601170 <acc> # +49.54%
13.82 : 4005c6: sub $0x1,%rax
0.46 : 4005ca: mov %rax,0x200b9f(%rip) # 601170 <acc>
2.30 : 4005d1: mov -0x10(%rbp),%rax # +50.46%
0.46 : 4005d5: mov %rax,%rdi
0.46 : 4005d8: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 4005dd: mov %rax,-0x10(%rbp) # +100.00%
0.92 : 4005e1: mov -0x18(%rbp),%rax
0.00 : 4005e5: and $0x1,%eax
0.00 : 4005e8: test %rax,%rax
0.00 : 4005eb: je 4005ff <branches+0x85> # -100.00% (p:100.00%)
0.00 : 4005ed: mov 0x200b7c(%rip),%rax # 601170 <acc>
0.00 : 4005f4: shr $0x2,%rax
0.00 : 4005f8: mov %rax,0x200b71(%rip) # 601170 <acc>
0.00 : 4005ff: mov -0x10(%rbp),%rax # +100.00%
7.37 : 400603: and $0x1,%eax
3.69 : 400606: test %rax,%rax
0.00 : 400609: jne 400612 <branches+0x98> # -59.25% (p:42.99%)
1.84 : 40060b: mov $0x1,%eax
14.29 : 400610: jmp 400617 <branches+0x9d> # -100.00% (p:100.00%)
1.38 : 400612: mov $0x0,%eax # +57.65%
10.14 : 400617: test %al,%al # +42.35%
0.00 : 400619: je 40062f <branches+0xb5> # -57.65% (p:100.00%)
0.46 : 40061b: mov 0x200b4e(%rip),%rax # 601170 <acc>
2.76 : 400622: sub $0x1,%rax
0.00 : 400626: mov %rax,0x200b43(%rip) # 601170 <acc>
0.46 : 40062d: jmp 400641 <branches+0xc7> # -100.00% (p:100.00%)
0.92 : 40062f: mov 0x200b3a(%rip),%rax # 601170 <acc> # +56.13%
2.30 : 400636: add $0x1,%rax
0.92 : 40063a: mov %rax,0x200b2f(%rip) # 601170 <acc>
0.92 : 400641: mov -0x10(%rbp),%rax # +43.87%
2.30 : 400645: mov %rax,%rdi
0.00 : 400648: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 40064d: mov %rax,-0x10(%rbp) # +100.00%
1.84 : 400651: addq $0x1,-0x8(%rbp)
0.92 : 400656: mov -0x8(%rbp),%rax
5.07 : 40065a: cmp -0x20(%rbp),%rax
0.00 : 40065e: jb 40059f <branches+0x25> # -100.00% (p:100.00%)
0.00 : 400664: nop
0.00 : 400665: leaveq
0.00 : 400666: retq
(Note: the --branch-filter u,any was used to avoid spurious target and
branch points due to interrupts/faults, they show up as very small -/+
annotations on 'weird' locations)
Committer note:
Please take a look at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
To see the colors.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Anshuman Khandual <khandual@linux.vnet.ibm.com>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
[ Moved sym->max_coverage to 'struct annotate', aka symbol__annotate(sym) ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
We were just using pr_error() which makes it difficult for non stdio UIs
to provide errors using its widgets, as they need to somehow catch what
was passed to pr_error().
Fix it by introducing a __strerror() interface like the ones used
elsewhere, for instance target__strerror().
This is just the initial step, more work will be done, but first some
error handling bugs noticed while working on this need to be dealt with.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-dgd22zl2xg7x4vcnoa83jxfb@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Compute the IPC and the basic block cycles for the annotate display.
IPC is computed by counting the instructions, and then dividing the
accounted cycles by that count.
The actual IPC computation can only be done at annotate time, because we
need to parse the objdump output first to know the number of
instructions in the basic block.
The cycles/IPC are also put into the perf function annotation so that
the display code can show them.
Again basic block overlaps are not handled, with the longest winning,
but there are some heuristics to hide the IPC when the longest is not
the most common.
v2: Compute IPC correctly.
Signed-off-by: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1437233094-12844-6-git-send-email-andi@firstfloor.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This adds the basic infrastructure to keep track of cycle counts per
basic block for annotate. We allocate an array similar to the normal
accounting, and then account branch cycles there.
We handle two cases:
cycles per basic block with start and cycles per branch (these are later
used for either IPC or just cycles per BB)
In the start case we cannot handle overlaps, so always the longest basic
block wins.
For the cycles per branch case everything is accurately accounted.
v2: Remove unnecessary checks. Slight restructure. Move
symbol__get_annotation to another patch. Move histogram allocation.
v3: Merged with current tree
Signed-off-by: Andi Kleen <ak@linux.intel.com>
Acked-by: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1437233094-12844-4-git-send-email-andi@firstfloor.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Currently the symbol structure is allocated with symbol_conf.priv_size
to carry sideband information like annotation, map browser on TUI and
sort-by-name tree node. So retrieving these information from symbol
needs to care about the details of such placement.
However the annotation code just assumes that the symbol is placed after
the struct annotation. But actually there's other info between them.
So accessing those struct will lead to an undefined behavior (usually a
crash) after they write their info to the same location.
To reproduce the problem, please follow the steps below:
1. run perf report (TUI of course) with -v option
2. open map browser (by pressing right arrow key for any entry)
3. search any function (by pressing '/' key and input whatever..)
4. return to the hist browser (by pressing 'q' or left arrow key)
5. open annotation window for the same entry (by pressing 'a' key)
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: David Ahern <dsahern@gmail.com>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1421234288-22758-1-git-send-email-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
With srcline key/sort'ing it's useful to have line numbers in the
annotate window. This patch implements this.
Use objdump -l to request the line numbers and save them in the line
structure. Then the browser displays them for source lines.
The line numbers are not displayed by default, but can be toggled on
with 'k'
There is one unfortunate problem with this setup. For lines not
containing source and which are outside functions objdump -l reports
line numbers off by a few: it always reports the first line number in
the next function even for lines that are outside the function.
I haven't found a nice way to detect/correct this. Probably objdump has
to be fixed.
See https://sourceware.org/bugzilla/show_bug.cgi?id=16433
The line numbers are still useful even with these problems, as most are
correct and the ones which are not are nearby.
v2: Fix help text. Handle (discriminator...) output in objdump.
Left align the line numbers.
Signed-off-by: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1415844328-4884-9-git-send-email-andi@firstfloor.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The TUI of perf report and top support annotation, but stdio and GTK
don't. So it should be checked before calling hist_entry__inc_addr_
samples() to avoid wasting resources that will never be used.
perf annotate need it regardless of UI and sort keys, so the check
of whether to allocate resources should be on the tools that have
annotate as an option in the TUI, 'report' and 'top', not on the
function called by all of them.
It caused perf annotate on ppc64 to produce zero output, since the
buckets were not being allocated.
Reported-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Anton Blanchard <anton@samba.org>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Paul Mackerras <paulus@samba.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1392859976-32760-1-git-send-email-namhyung@kernel.org
[ Renamed (report,top)__needs_annotate() to ui__has_annotation() ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Dynamically allocate source_line_percent according to a number of group
members and save nr_pcnt to the struct source_line. This way we can
handle multiple events in a general manner.
However since the size of struct source_line is not fixed anymore,
iterating whole source_line should care about its size.
$ perf annotate --group --stdio --print-line
Sorted summary for file /lib/ld-2.11.1.so
----------------------------------------------
33.33 0.00 /build/buildd/eglibc-2.11.1/elf/rtld.c:381
33.33 0.00 /build/buildd/eglibc-2.11.1/elf/dynamic-link.h:128
33.33 0.00 /build/buildd/eglibc-2.11.1/elf/do-rel.h:105
0.00 75.00 /build/buildd/eglibc-2.11.1/elf/dynamic-link.h:137
0.00 25.00 /build/buildd/eglibc-2.11.1/elf/dynamic-link.h:187
...
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Paul Mackerras <paulus@samba.org>
Cc: Pekka Enberg <penberg@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1362462812-30885-9-git-send-email-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The --print-line option of perf annotate command shows summary for
each source line. But it didn't merge same lines so that it can
appear multiple times.
* before:
Sorted summary for file /home/namhyung/bin/mcol
----------------------------------------------
21.71 /home/namhyung/tmp/mcol.c:26
20.66 /home/namhyung/tmp/mcol.c:25
9.53 /home/namhyung/tmp/mcol.c:24
7.68 /home/namhyung/tmp/mcol.c:25
7.67 /home/namhyung/tmp/mcol.c:25
7.66 /home/namhyung/tmp/mcol.c:26
7.49 /home/namhyung/tmp/mcol.c:26
6.92 /home/namhyung/tmp/mcol.c:25
6.81 /home/namhyung/tmp/mcol.c:25
1.07 /home/namhyung/tmp/mcol.c:26
0.52 /home/namhyung/tmp/mcol.c:25
0.51 /home/namhyung/tmp/mcol.c:25
0.51 /home/namhyung/tmp/mcol.c:24
* after:
Sorted summary for file /home/namhyung/bin/mcol
----------------------------------------------
50.77 /home/namhyung/tmp/mcol.c:25
37.94 /home/namhyung/tmp/mcol.c:26
10.04 /home/namhyung/tmp/mcol.c:24
To do that, introduce percent_sum field so that the normal
line-by-line output doesn't get changed.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Paul Mackerras <paulus@samba.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1352440729-21848-1-git-send-email-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
perf defines both __used and __unused variables to use for marking
unused variables. The variable __used is defined to
__attribute__((__unused__)), which contradicts the kernel definition to
__attribute__((__used__)) for new gcc versions. On Android, __used is
also defined in system headers and this leads to warnings like: warning:
'__used__' attribute ignored
__unused is not defined in the kernel and is not a standard definition.
If __unused is included everywhere instead of __used, this leads to
conflicts with glibc headers, since glibc has a variables with this name
in its headers.
The best approach is to use __maybe_unused, the definition used in the
kernel for __attribute__((unused)). In this way there is only one
definition in perf sources (instead of 2 definitions that point to the
same thing: __used and __unused) and it works on both Linux and Android.
This patch simply replaces all instances of __used and __unused with
__maybe_unused.
Signed-off-by: Irina Tirdea <irina.tirdea@intel.com>
Acked-by: Pekka Enberg <penberg@kernel.org>
Cc: David Ahern <dsahern@gmail.com>
Cc: Ingo Molnar <mingo@redhat.com>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Paul Mackerras <paulus@samba.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Steven Rostedt <rostedt@goodmis.org>
Link: http://lkml.kernel.org/r/1347315303-29906-7-git-send-email-irina.tirdea@intel.com
[ committer note: fixed up conflict with a116e05 in builtin-sched.c ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
{kind=link}