IF YOU WOULD LIKE TO GET AN ACCOUNT, please write an
email to Administrator. User accounts are meant only to access repo
and report issues and/or generate pull requests.
This is a purpose-specific Git hosting for
BaseALT
projects. Thank you for your understanding!
Только зарегистрированные пользователи имеют доступ к сервису!
Для получения аккаунта, обратитесь к администратору.
When read the code: `pager.AddParam(ctx, "search", "search")`, the
question always comes: What is it doing? Where is the value from? Why
"search" / "search" ?
Now it is clear: `pager.AddParamIfExist("search", ctx.Data["search"])`
just some refactoring bits towards replacing **util.OptionalBool** with
**optional.Option[bool]**
---------
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
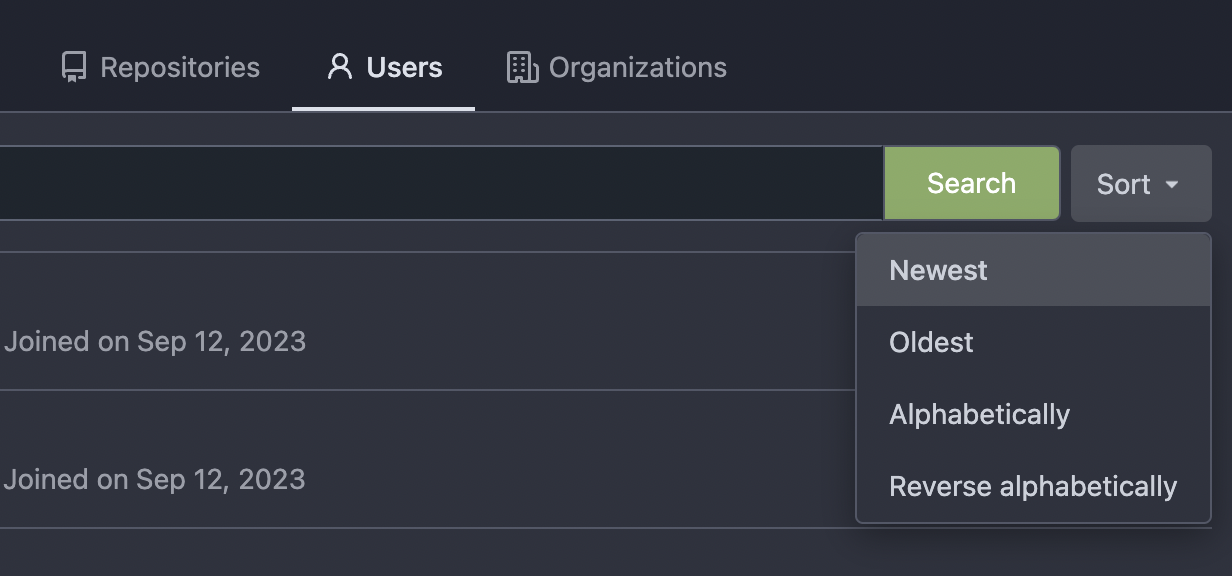
Thanks to inferenceus : some sort orders on the "explore/users" page
could list users by their lastlogintime/updatetime.
It leaks user's activity unintentionally. This PR makes that page only
use "supported" sort orders.
Removing the "sort orders" could also be a good solution, while IMO at
the moment keeping the "create time" and "name" orders is also fine, in
case some users would like to find a target user in the search result,
the "sort order" might help.
Since `modules/context` has to depend on `models` and many other
packages, it should be moved from `modules/context` to
`services/context` according to design principles. There is no logic
code change on this PR, only move packages.
- Move `code.gitea.io/gitea/modules/context` to
`code.gitea.io/gitea/services/context`
- Move `code.gitea.io/gitea/modules/contexttest` to
`code.gitea.io/gitea/services/contexttest` because of depending on
context
- Move `code.gitea.io/gitea/modules/upload` to
`code.gitea.io/gitea/services/context/upload` because of depending on
context
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
releated to #21820
- Split `Size` in repository table as two new colunms, one is `GitSize`
for git size, the other is `LFSSize` for lfs data. still store full size
in `Size` colunm.
- Show full size on ui, but show each of them by a `title`; example:
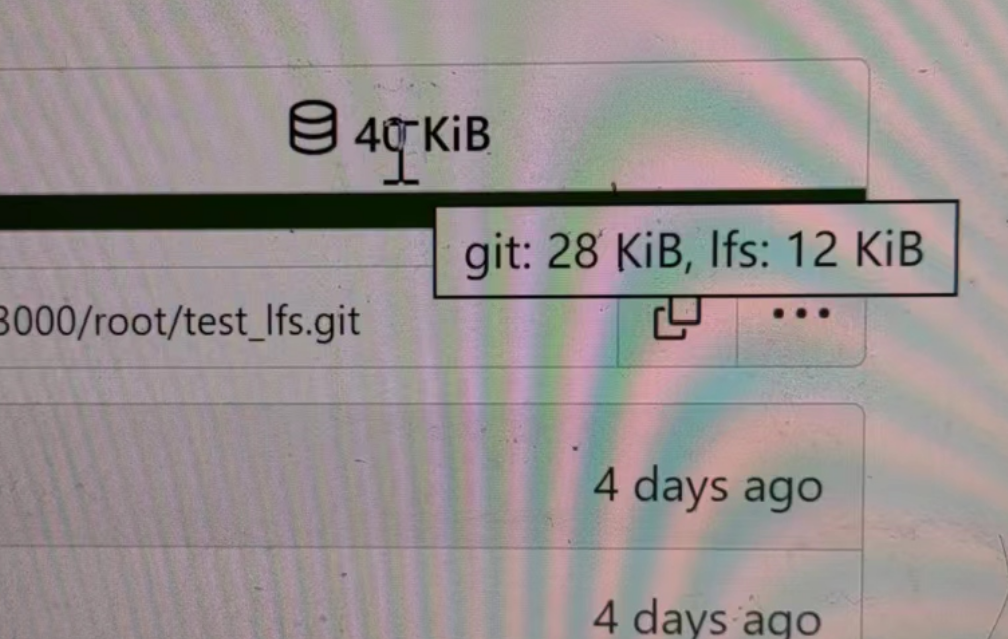
- Return full size in api response.
---------
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: DmitryFrolovTri <23313323+DmitryFrolovTri@users.noreply.github.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Refactor `modules/indexer` to make it more maintainable. And it can be
easier to support more features. I'm trying to solve some of issue
searching, this is a precursor to making functional changes.
Current supported engines and the index versions:
| engines | issues | code |
| - | - | - |
| db | Just a wrapper for database queries, doesn't need version | - |
| bleve | The version of index is **2** | The version of index is **6**
|
| elasticsearch | The old index has no version, will be treated as
version **0** in this PR | The version of index is **1** |
| meilisearch | The old index has no version, will be treated as version
**0** in this PR | - |
## Changes
### Split
Splited it into mutiple packages
```text
indexer
├── internal
│ ├── bleve
│ ├── db
│ ├── elasticsearch
│ └── meilisearch
├── code
│ ├── bleve
│ ├── elasticsearch
│ └── internal
└── issues
├── bleve
├── db
├── elasticsearch
├── internal
└── meilisearch
```
- `indexer/interanal`: Internal shared package for indexer.
- `indexer/interanal/[engine]`: Internal shared package for each engine
(bleve/db/elasticsearch/meilisearch).
- `indexer/code`: Implementations for code indexer.
- `indexer/code/internal`: Internal shared package for code indexer.
- `indexer/code/[engine]`: Implementation via each engine for code
indexer.
- `indexer/issues`: Implementations for issues indexer.
### Deduplication
- Combine `Init/Ping/Close` for code indexer and issues indexer.
- ~Combine `issues.indexerHolder` and `code.wrappedIndexer` to
`internal.IndexHolder`.~ Remove it, use dummy indexer instead when the
indexer is not ready.
- Duplicate two copies of creating ES clients.
- Duplicate two copies of `indexerID()`.
### Enhancement
- [x] Support index version for elasticsearch issues indexer, the old
index without version will be treated as version 0.
- [x] Fix spell of `elastic_search/ElasticSearch`, it should be
`Elasticsearch`.
- [x] Improve versioning of ES index. We don't need `Aliases`:
- Gitea does't need aliases for "Zero Downtime" because it never delete
old indexes.
- The old code of issues indexer uses the orignal name to create issue
index, so it's tricky to convert it to an alias.
- [x] Support index version for meilisearch issues indexer, the old
index without version will be treated as version 0.
- [x] Do "ping" only when `Ping` has been called, don't ping
periodically and cache the status.
- [x] Support the context parameter whenever possible.
- [x] Fix outdated example config.
- [x] Give up the requeue logic of issues indexer: When indexing fails,
call Ping to check if it was caused by the engine being unavailable, and
only requeue the task if the engine is unavailable.
- It is fragile and tricky, could cause data losing (It did happen when
I was doing some tests for this PR). And it works for ES only.
- Just always requeue the failed task, if it caused by bad data, it's a
bug of Gitea which should be fixed.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
This gives more "freshness" to the explore page. So it's not just the
same X users on the explore page by default, now it matches the same
sort as the repos on the explore page.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Follow #21962
After I eat my own dogfood, I would say that
ONLY_SHOW_RELEVANT_REPOS=false is necessary for many private/enterprise
instances, because many private repositories do not have
"description/topic", users just want to search by their names.
This PR also adds `PageIsExploreRepositories` check, to make code more
strict, because the `search` template is shared for different purpose.
And during the test, I found a bug that the "Search" button didn't
respect the "relevant" parameter, so this PR fixes the bug by the way
together.
I think this PR needs to be backported.
Every user can already disable the filter manually, so the explicit
setting is absolutely useless and only complicates the logic.
Previously, there was also unexpected behavior when multiple query
parameters were present.
---------
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Change all license headers to comply with REUSE specification.
Fix#16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
This PR adds a context parameter to a bunch of methods. Some helper
`xxxCtx()` methods got replaced with the normal name now.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This prevents a 500 response, because null pointer exceptions in
rendering the template.
This happends bc the repoId is not in the repoMap because it is delete
fix#19076
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Adds a new option to only show relevant repo's on the explore page, for bigger Gitea instances like Codeberg this is a nice option to enable to make the explore page more populated with unique and "high" quality repo's. A note is shown that the results are filtered and have the possibility to see the unfiltered results.
Co-authored-by: vednoc <vednoc@protonmail.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
* When non-admin users use code search, get code unit accessible repos in one main query
* Modified some comments to match the changes
* Removed unnecessary check for Access Mode in Collaboration table
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
* Move some repository related code into sub package
* Move more repository functions out of models
* Fix lint
* Some performance optimization for webhooks and others
* some refactors
* Fix lint
* Fix
* Update modules/repository/delete.go
Co-authored-by: delvh <dev.lh@web.de>
* Fix test
* Merge
* Fix test
* Fix test
* Fix test
* Fix test
Co-authored-by: delvh <dev.lh@web.de>
Reusing `/api/v1` from Gitea UI Pages have pros and cons.
Pros:
1) Less code copy
Cons:
1) API/v1 have to support shared session with page requests.
2) You need to consider for each other when you want to change something about api/v1 or page.
This PR moves all dependencies to API/v1 from UI Pages.
Partially replace #16052
* Some refactors related repository model
* Move more methods out of repository
* Move repository into models/repo
* Fix test
* Fix test
* some improvements
* Remove unnecessary function
It makes Admin's life easier to filter users by various status.
* introduce window.config.PageData to pass template data to javascript module and small refactor
move legacy window.ActivityTopAuthors to window.config.PageData.ActivityTopAuthors
make HTML structure more IDE-friendly in footer.tmpl and head.tmpl
remove incorrect <style class="list-search-style"></style> in head.tmpl
use log.Error instead of log.Critical in admin user search
* use LEFT JOIN instead of SubQuery when admin filters users by 2fa. revert non-en locale.
* use OptionalBool instead of status map
* refactor SearchUserOptions.toConds to SearchUserOptions.toSearchQueryBase
* add unit test for user search
* only allow admin to use filters to search users
Followup from #16562 prepare for #16567
* Rename ctx.Form() to ctx.FormString()
* Reimplement FormX func to need less code and cpu cycles
* Move code into own file
{kind=link}
{kind=link}