|
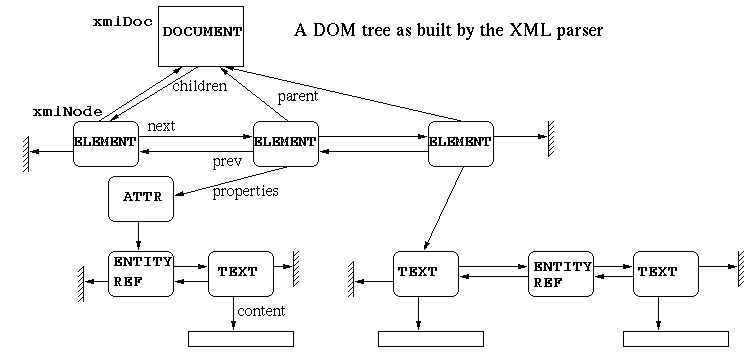
The parser returns a tree built during the document analysis. The value
returned is an xmlDocPtr (i.e., a pointer to an
xmlDoc structure). This structure contains information such
as the file name, the document type, and a children pointer
which is the root of the document (or more exactly the first child under the
root which is the document). The tree is made of xmlNodes,
chained in double-linked lists of siblings and with a children<->parent
relationship. An xmlNode can also carry properties (a chain of xmlAttr
structures). An attribute may have a value which is a list of TEXT or
ENTITY_REF nodes.
Here is an example (erroneous with respect to the XML spec since there
should be only one ELEMENT under the root):
In the source package there is a small program (not installed by default)
called xmllint which parses XML files given as argument and
prints them back as parsed. This is useful for detecting errors both in XML
code and in the XML parser itself. It has an option --debug
which prints the actual in-memory structure of the document; here is the
result with the example given before:
DOCUMENT
version=1.0
standalone=true
ELEMENT EXAMPLE
ATTRIBUTE prop1
TEXT
content=gnome is great
ATTRIBUTE prop2
ENTITY_REF
TEXT
content= linux too
ELEMENT head
ELEMENT title
TEXT
content=Welcome to Gnome
ELEMENT chapter
ELEMENT title
TEXT
content=The Linux adventure
ELEMENT p
TEXT
content=bla bla bla ...
ELEMENT image
ATTRIBUTE href
TEXT
content=linus.gif
ELEMENT p
TEXT
content=...
This should be useful for learning the internal representation model.
Daniel Veillard
| 

